Abstract
Classifier-free Guidance (CFG) is a widely used technique in modern diffusion models for enhancing sample quality and prompt adherence. However, through an empirical analysis on Gaussian mixture modeling with a closed-form solution, we observe a discrepancy between the suboptimal results produced by CFG and the ground truth. The model's excessive reliance on these suboptimal predictions often leads to semantic incoherence and low-quality outputs. To address this issue, we first empirically demonstrate that the model's suboptimal predictions can be effectively refined using sub-networks of the model itself. Building on this insight, we propose S2-Guidance, a novel method that leverages stochastic block-dropping during the forward process to construct sub-networks, effectively guiding the model away from potential low-quality predictions and toward high-quality outputs. Extensive qualitative and quantitative experiments on text-to-image and text-to-video generation tasks demonstrate that S2-Guidance delivers superior performance, consistently surpassing CFG and other advanced guidance strategies. Our code will be released.
Method
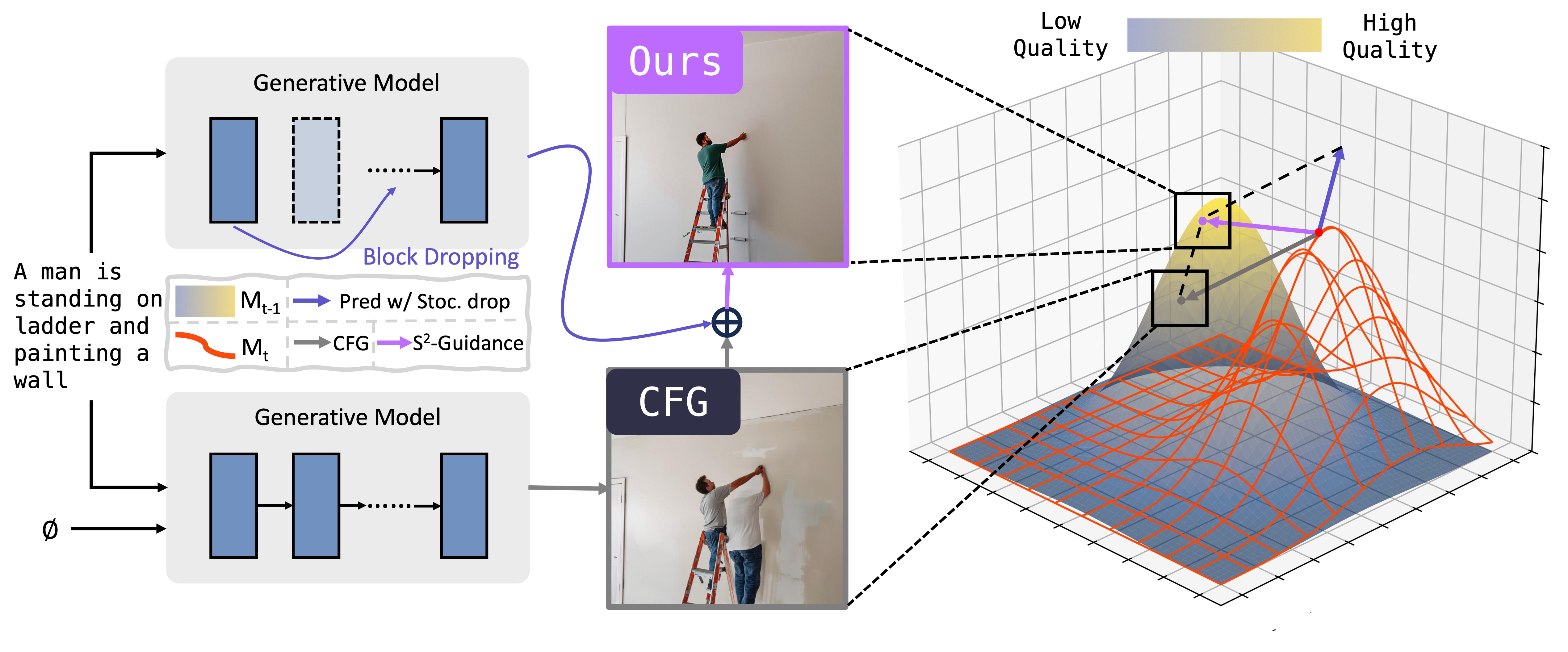
An illustration of our guidance mechanism on the generation quality manifold. The current state of generation (Mt, orange wireframe) is guided towards the next state (Mt-1). Original CFG provides a strong but suboptimal direction (gray arrow), failing to precisely target the high-quality region (yellow peak). Ours refines this by computing a self-corrective prediction from a stochastically block-dropping strategy (Pred w/ Stoc. drop, blue arrow). The resulting Ours vector (purple arrow) steers the update towards the optimal region of the generation manifold, resulting in higher-fidelity outputs.
Gallery
Text to Image Generation


Prompt: "The bold dramatic strokes of the painter's brush created a stunning abstract masterpiece a work of emotional depth and intensity."


Prompt: "A floating castle above the clouds, with 'S2 Guidance Is All You Need' swirling in the mist."


Prompt: "A woman is holding a bouquet of balloons and celebrating a birthday."


Prompt: "A red book and an ivory sheep. "


Prompt: "A cat sitting besides a rocket on a planet with a lot of cactuses."


Prompt: "A woman sitting under an umbrella in the middle of a restaurant."
Text to Video Generation
Prompt: "A breathtaking close-up of a woman frozen in time as golden threads of light weave around her face, creating dynamic flowing patterns of energy amidst glowing particles."
Prompt: "An astronaut flying in space."
Prompt: "A car accelerating to gain speed."
Prompt: "A close-up of a beautiful woman's face with colored powder exploding around her, creating an abstract splash of vibrant hues."
Citation
If you find our work useful for your research, please feel free to leave a ⭐Star⭐ and cite our paper:
@article{chen2025s,
title={S $\^{} 2$-Guidance: Stochastic Self Guidance for Training-Free Enhancement of Diffusion Models},
author={Chen, Chubin and Zhu, Jiashu and Feng, Xiaokun and Huang, Nisha and Wu, Meiqi and Mao, Fangyuan and Wu, Jiahong and Chu, Xiangxiang and Li, Xiu},
journal={arXiv preprint arXiv:2508.12880},
year={2025}
}